Mapping Terrain With In-Depth Recon
Introduction
This guide is about assessing an organization’s attack surface through the lens of application security. When I refer to attack surface, I mean the totality of endpoints that an organization has exposed to the public and are thus are able to be attacked. Most would agree that it is not glamorous to account for your devices and applications, but if an organization is not aware of an endpoint’s existence, it will likely not receive regular updates and could easily become a weak point in your organization’s defenses. I have noticed this trend time and again during assessments when I uncover an unpatched Jenkins or Exchange server that I then use to pivot into the internal network.
It has been argued that Web Application Firewalls (WAFs) and automated scanners effectively mitigate the issue of exposed unpatched systems. These two tools do perform a necessary function, but their combination does not solve the attack surface problem, especially for large organizations. I have often encountered false negatives for popular scanners like Nessus and Nuclei as well as come across nasty access control vulnerabilities on forgotten systems that are unable to be protected by WAFs or discovered by scanners due to the nature of the vulnerability. In such cases, we need to incorporate some manual components into our defensive posture to ensure adequate coverage.
The goal of this presentation is to demonstrate the application hacker’s methodology and hopefully provide perspective on how hackers hunt your apps. Attackers generally want to break a mixture of Confidentiality, Integrity, or Availability (CIA) and thus our approach should focus on answering questions similar to the following:
- Does this data entry point allow us to affect the integrity of the application’s data?
- Can we abuse this functionality to cause a denial of service?
- Should this information be available to us? Can we circumvent an access control to obtain confidential information?
Ultimately the answers to these questions depend on what the organization defines as acceptable. Hence, it is generally a good idea to identify what types of information the organization finds important. For instance, if the target organization is a government entity, they may not care if someone can abuse an Insecure Direct Object Reference (IDOR) bug to retrieve public documents because they are intended to be viewed by everyone. However, the same bug may be immediately fixed if it can also retrieve internal meeting minutes or Personally Identifiable Information. We should focus on endpoints and bug classes that can impact one of the pillars of the CIA triad in a way that the target organization finds meaningful.
Reconnaissance 🕵
Note: This guide is focused on application security. Thus, I will not be covering phishing, social engineering, or post-exploitation in this guide.
Our Goals for this phase
- Map as many of the target’s online endpoints as possible
- Collect subdomains
- Find those endpoints they don’t want you to know about
Reconnaissance allows us to create a mind map of the organization’s overall online presence. In this phase, we aim to identify infrastructure patterns, how the organization is hosted (on prem vs cloud-based), and if they utilize a Content Delivery Network (CDN). This will provide us an attack surface for the following phases.
The target’s attack surface management will be key here as you can’t patch what you don’t know about. Hence our attention will be drawn to older technologies and low-hanging fruit first.
The last few years have been a corporate merger paradise, which has proved to be a breeding ground for asset mismanagement. Even government departments merge and assets get lost in the sauce. These lost assets generally become ripe targets over time.
Typically, the bots scraping the internet will scoop up the low-hanging fruit, but there are many assets that are unable to be identified by scanners like nuclei for various reasons including WAFs and/or custom ports/paths. With a handful of tools, we can easily map out a target organization and look for things that can’t (easily) be signatured.
If you’re interested in a case study on poor asset management, you can read or listen about how a forgotten SQL server led to a massive breach in a UK Telecom company.
Now let’s dive into how you can look for potentially sensitive or forgotten assets.
Note: this guide assumes access to a Linux distribution such as Kali, Parrot, Ubuntu, WSL, etc.
Gathering domains
Tools used:
Note: If you would like to see steps on installing any tools in this guide, please navigate to the tools appendix.
In this step, we’re looking to gather as many subdomains or assets as possible within the scope of our assessment. In the code snippet below, we will utilize several tools to map out the attack surface of example.com
Amass will query various online resources for your target domain including TLS certificate registrations, ThreatCrowd, Alienvault, passiveDNS, ASN lookup, censys, etc. The result will be a list of subdomains in amass1.txt.
amass enum -d example.com -o amass1.txt
Next, we will use Tomnomnom’s assetfinder to locate other assets that amass may have missed.
assetfinder example.com >> assetfinder1.txt
Next, we will feed our domains to subfinder to increase our coverage. We will also feed this output back into subfinder to crawl further up the subdomains chains for additional endpoints.
subfinder -d example.com -o subfinder1.txt
cat assetfinder1.txt subfinder1.txt amass1.txt subfinder1.txt | anew subfinder.txt
subfinder -dL subfinder.txt -o full -timeout 5 -silent | anew domains
Finally, let’s leverage additional passive scanning tools to generate even more domains we may have missed
GITHUB_TOKEN=YOUR_GITHUB_TOKEN_HERE ~/git/github-subdomains/github-subdomains -d example.com -o gitdoms
cat gitdoms | anew domains
shodan search --fields hostnames hostname:*.$1 | sed 's/;/\n/g' | anew domains
shodan search --fields hostnames ssl.cert.subject.cn:*.$1 | sed 's/;/\n/g' | anew domains
The result should ideally be a large list of newline-separated domains that looks like this:
example.com
mail.example.com
...
int.example.com
stg-www-example.com
Optional step: You can use dnsgen to guess additional subdomains based on your current domain list. So if you feed the above excerpt of example.com domains, dns-gen will try to guess int2.example.com, mail-stg.example.com, int-stg-mail.example.com and so on. Link to dnsgen and Link to resolvers.txt
# Generate and brute force new domains based on pre-discovered domains.
cat domains | dnsgen - | massdns -r ~/resolvers.txt -t A -o L --flush 2>/dev/null | anew dns-gen-domains
cat dns-gen-domains | anew domains && rm -f dns-gen-domains
Finally, I will use grep to ensure that we stick to our scope: (this assumes a scope of *.example.com). If you skip this step, you will potentially have a lot of junk in your domain list that isn’t related to your target organization. It will waste your time and resources, so it’s better to filter now rather than later.
grep "example.com" domains > in-scope-domains
Finding active endpoints
I prefer httpx from projectdiscovery for mapping out online hosts. Some folks prefer masscan or nmap. It doesn’t really matter what tool you use, as long as you like the output format and it is performant.
In the below snippet, httpx will retry 3 times on ports 80,443,8080, and 8443. I also placed a rate-limit of 50 requests per second. The default is 150, but I find that I can sometimes get filtered early on if the target organization utilizes certain CDNs. In some cases, I’ve had to drop it to 1 request per second so that I could accurately map endpoints without getting dropped.
cat in-scope-domains | httpx -retries 3 -random-agent -p 80,443,8080,8443 -rl 50 | anew online-hosts
Due to the fact that our domains file can be tens of thousands of entries, the above line may take a while. I usually fill this time by looking through shodan or censys results using the
hostname:*.example.comandorg:example company, llcfilters to manually inspect strange ports or technologies that I don’t typically scan for.
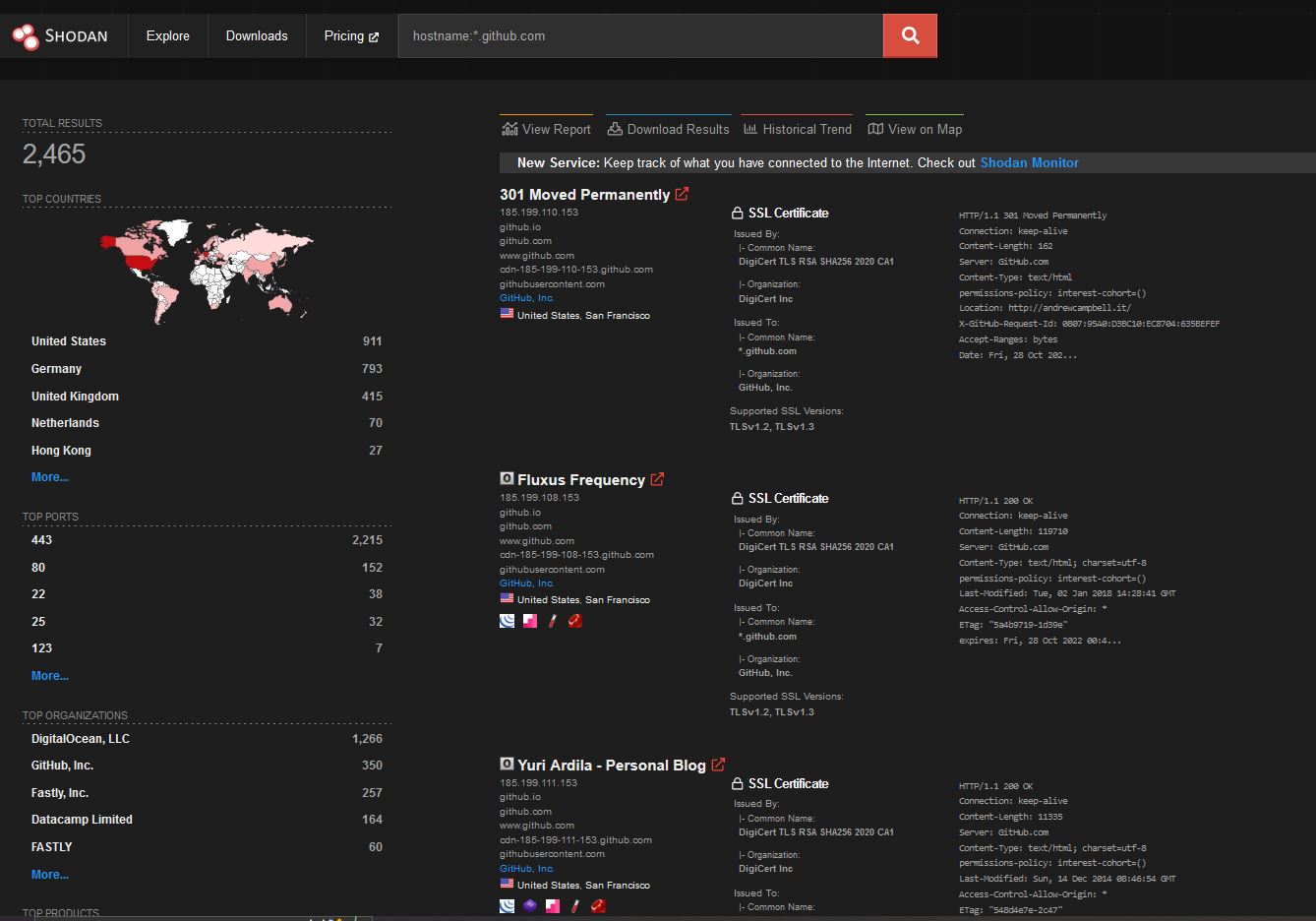
After it finishes, the result will be a link of the format https://sub.example.com:port on each line.
It can also be helpful to navigate to google.com while waiting for scans to complete and use the following dorks to look for content:hostname:*.example.com
This will likely return many links on the primary subdomains. We can filter out content using the - operator. For example, -www.example.com will remove all results from www.example.com. This process can reveal some interesting sites as well as content blurbs to help guide you to something juicy.
This concludes the reconnaissance portion.
Content Discovery 🔭
Our Goal for this phase
- Look for internal or sensitive titles/domains (Exposed JBOSS, Jenkins, PeopleSoft, Solr, MongoDB, etc.)
- Identify technology stacks used in the target environment (Apache Tomcat, Citrix, VMWare, Wordpress)
- Find applications we can interact with that accept input.
Note if you are performing a white-box assessment, you can probably skip to identifying data entry points. The below is really only useful for black-box assessments where you have no way of knowing what applications are hosted on what endpoints.
Tools for this phase
| Choose one: Feroxbuster | Ffuf | Gobuster | Turbo Intruder |
There are a couple of methods to help guide our discovery phase from here:
- Screenshot all endpoints using eyewitness or gowitness, then review screenshots for interesting applications.
- Slower and a pain to manually review
- Grab titles and content lengths to get a basic idea of what an endpoint is hosting.
- Faster but not as accurate as seeing the page
I prefer using httpx to grab titles so that I can filter out uninteresting endpoints using grep. Below is an httpx line to gather site titles.
cat online-hosts | httpx -rl 50 -retries 3 -timeout 7 -random-agent -follow-redirects -nc -cl -title | anew titles
There are a lot of options in this snippet, so I’ll break it down:
- rl : rate-limit aka requests per second. Keep it reasonable (or don’t I’m not a cop)
- retries : how many times it will retry the resource. I’ve seen this prevent false negatives, especially if you’re going with a high request rate.
- timeout : the default is 5 seconds, but I like to increase it because some old servers are slow
- random-agent : randomizes the user agent string to prevent some firewalls from flagging us
- follow-redirects : Follow a redirect from / to /endpoint so we can retrieve the title for what we care about
- nc : no color. This will save us headaches when grepping through the output. If you like pretty colors, take this off.
- cl : content-length. WAFs will usually return a static content length when a resource is blocked, so this lets us filter those endpoints out.
- title : Grabs the title of the endpoint.
- sc : (optional) Display status-code e.g. 200,403,500. Can be useful in certain environments. However, status codes don’t mean a whole lot these days. Many apps return a 200 and then the content is
resource not found. If you develop apps and do this, please stop hurting me.
All of these together will result in the following list of titles and content lengths:
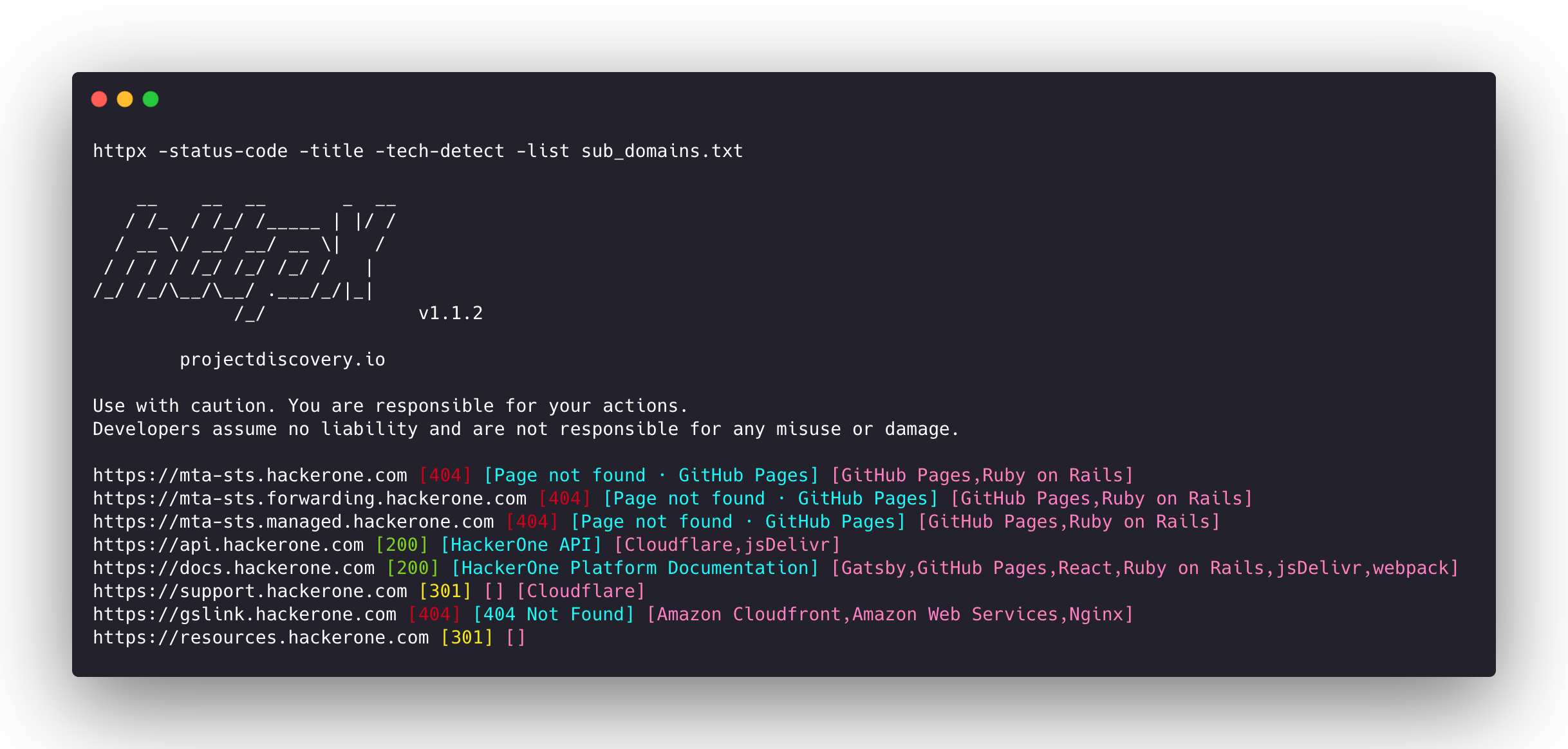
Note: Most of the tools used below can be configured to output in JSON. Feel free to substitute grep and vim with your text editor of choice. The idea is that we can easily filter out the junk with negative searches like egrep -v.
Now it’s time to go through our output. Depending on the number of endpoints, this could be large. I prefer to open the results in vim, but you can also page through it with less or another text editor like vscode or sublime.
cat titles | less
# or use vim
vim titles
As you go through them, you will see similar titles and content lengths. For example, let’s say your organization has 30 different static blogs. You can use egrep to filter the blog title egrep -v "blog title" titles | less or use vim %! egrep -v blog-title. I will also usually see the same site hosted for different countries such as au.example.com uk.example.com, etc. The content length and title should generally be the same and you can use the same filter tricks to remove the junk.
Here are the titles I’m usually interested in:
- Not found –> Usually indicates something is being hosted but without a redirect from the web root.
- Forbidden –> Occasionally has paths accessible that may be incorrectly configured and reveal sensitive information.
- Sensitive title –> Titles that indicate sensitive information is stored on the application (SSN / billing / corp)
- Esoteric technology banner –> Don’t recognize the server? It’s probably old and busted.
- Internal / Corp / File upload related titles
Note: Often a WAF or CDN will return a 200 with a static title or content length for restricted resources. The title and content length returned by httpx provides an easy avenue to filter out these responses and narrow our attention to applications we can interact with.
Gathering URLs from interesting domains
Instead of immediately launching into forced browsing (i.e. brute forcing directories), the majority of application data entry points can be discovered via URL gathering.
Here we can use gau (Get All Urls) and waybackurls to pull from the Waybackmachine and AlienVault’s open threat exchange.
echo example.com | gau | anew urls
echo example.com | waybackurls | anew urls
Then you want to spider the site itself for URLs
gospider -d 5 -s example.com -q -t 10 -o .
cat example.com-urls | anew urls
This will result in a text file with a ton of links. Many of these will be garbage such as font or image files. Remember, we’re looking for places that accept input, so static assets are generally of no interest.
First I grab all queries such as /endpoint?file=example.jpg which are typically the bulk of our data entry points. Uro is a tool that will remove duplicate queries such as /endpoint?file=example.png. We already have the first query and don’t really care about additional file names being returned, especially if it’s something like doc1.xlsx and doc2.xsls etc.
egrep "\?" urls | uro | anew query-urls
Next, I clean out the static assets and the query stings to a separate file to view potentially sensitive directories
egrep -vi "\?|\.pdf|\.jpg|\.gif|\.png|\.gif|\.doc|\.ttf|\.woff|\.svg|\.eof|\.css|\.eot|\.xls" urls | anew non-query-urls
Each URL file is useful in a different way. We have query strings to look at, but we also want to be aware of api interfaces that may accept post requests over get parameters.
I spend a good amount of time from here reviewing the output on each url file. Here are some things to look for:
- proxy endpoints that accept URL parameters (e.g. proxy.ashx?url=http://example.com) –> Server-side Request Forgery
- Parameters with sequential values (e.g. id=1,2,3,4) –> Insecure Direct Object Reference / Access Control Issues
- Older extensions such as .asp or .nsf –> Generally more likely to be unpatched. Where there’s smoke there’s fire.
- Backups .old, .zip, .tar.gz , .tar.bz2 –> Credentials, Sensitive Data
- APIs documentation or API endpoints in general
- Not all APIs are intended to be interacted with directly by a user and can reveal sensitive information or allow an attacker to perform unintended actions
If you find something interesting, skip the content discovery for now. You can and should return to this phase if you hit a wall when testing.
Forced Browsing
However, If we strike out with the URLS, then we go with forced browsing. We will need a wordlist first. Here are a couple of different wordlists repositories we can use:
For now, we will stick with a directory brute force with a basic raft list
feroxbuser -w ~/git/SecLists/Discovery/Web-Content/raft-medium-directories-lowercase.txt -u https://example.com/ -A -k -r -d 4 -L 2 -o example.com-dump
Let’s break down the command:
- -w –> specify a wordlist to use. If the first line in the wordlist is apples it will request example.com/apples
- -u –> the url we want to browse e.g. example.com/
- -A –> Random user-agent
- -k –> Insecure TLS –> Often necessary because if an endpoint is old and forgotten, it probably has expired certs.
- -r –> Follow redirects
- -d 4–> depth 4 –> If feroxbuster discovers a directory, it will start another scan using the same list up to a depth of 4.
- -L 2 –> Limit 2 scans at once –> prevents us crashing the application (hopefully). May need to reduce to 1.
- -o example.com-dump –> dump the output of the scan to a file
You can pause the scan at any time by hitting enter. You can add custom filters or cancel scans and then resume the scan.
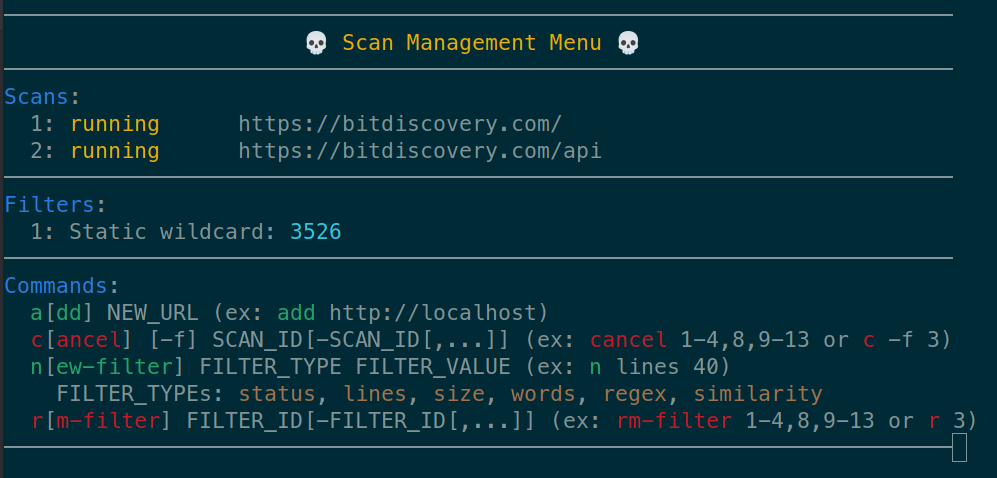
Additionally, if you ctrl-c the scan you can use --resume-from SATE_FILE to pick up where you left off.
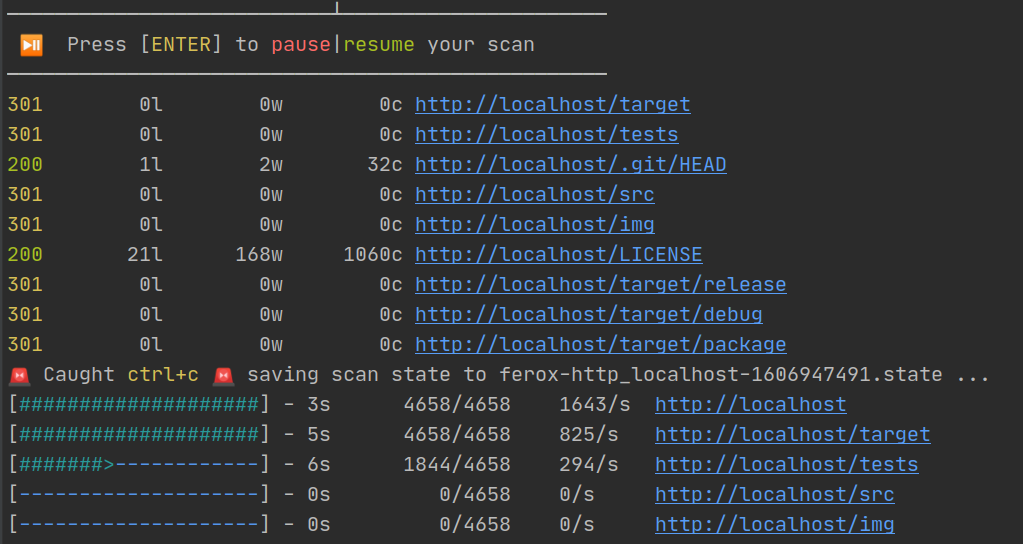
Now that we have some directories, we hopefully have a lead on some parts of the application that were not intended for us. Examples of these types of directories would be:
- Admin consoles
- Tomcat manager
- Monitoring interface
- Logging directory
- Uploads
- Services allowing us to query data sets e.g. Apache Solr, graphql, elastic
Strangely enough, I have found each of these at least once using a simple wordlist on an endpoint with “Not Found” at the webroot.
Once you have a list of directories and have identified the technology (i.e. .NET, Java, PHP, Node, REST API, CMS), you want to move to a file-based wordlist for each of the directories. There is no point using a php wordlist on a .NET site, so try to be deliberate when fuzzing for files.
In this example, we are fuzzing for aspx files in the app directory. This will not recurse (via -n) because we don’t want to request something like example.com/app/loader.aspx/help.aspx
feroxbuser -w ~/git/SecLists/Discovery/Web-Content/raft-medium-files-lowercase.txt -u https://example.com/app -A -k -r -n -L 2 -x aspx -o example.com-app-files-dump
At this point, it’s rinse and repeat of fuzzing for directories and then fuzzing for files. If you’re working on a restful API, then substitute files with API actions. This is due to APIs generally not being extension-based. I usually use a generic word-based list here or you can reuse an API-specific list from SecLists or Assetnote.
Note: It is often good practice to repeat your reconnaissance periodically as you will often discover new endpoints as time goes on.
Conclusion
Our goal in this phase was to give ourselves a decent attack surface. This is probably the most widely covered phase within the web application testing realm and is by far the easiest.
Once you have a sufficient number of endpoints to examine, you will want to move into the next phase: Identifying Data Entry Points. We will take interesting sites and strive to fully understand the application and frameworks involved. Once we understand the access controls, we can examine them for flaws.
This phase will be documented in the Application Hacking Methodology Part 2.